前情提要: 昨天嘗試使用LitServe部屬自己的model,看起來蠻正常的。
加上昨天花了點時間研究了官方docs,發現更多更好的寫法,以及如何測試benchmark,有更新前幾天的文章,補上連結及一些截圖,最後這邊來點總結。
經過這三四天的研究,LitServe的精簡跟pytorch lightning一樣讓我很喜歡,其中幾項對我來說蠻重要的:
可以想一下如果是要自己用fastapi寫這些功能有多難,所以我自己打算有時間也深入研究一下LitServe內部是怎麼寫的,感覺可以學到更多東西。
接下來我們來談談前幾天有用到的bert,我自己碩士剛學bert的時候只知道可以用在多種地方,但沒有深入了解,只由直接使用而已,沒有額外的training或fine-tune,直到進公司做的第一個專案就是跟bert有關。
bert的觀念參考連結我有放在前幾天當中,這裡就不贅述,主要就是能將一段文字,壓成一個特徵向量(embedding),輸出的維度可能是384, 768…,我們會透過這些embedding,再加一些網路,用一些資料進行特定的訓練,比如說摘要, 分類, 標點符號…,這個我們稱之為downstream task,那原先的bert訓練我們稱為upstream。
我一開始很疑惑,這個特徵向量有甚麼用,直到今年我開始做TTS,比較新的TTS架構會多加上類似bert這類LM的model,來幫助TTS學習"韻律",在三四年前的TTS你聽起來會覺得是假的,是因為他的韻律不對,有點類似機器人一個個字念的,但之前在推薦github那篇提到的TTS,你去聽會發現跟真人一樣,主要就是利用的LM壓出來的embedding,來學習字與詞的韻律關係,以下試著圖示講解。
# 安裝
pip install umap-learn
應該聽過PCA或tsne來降維,那umap效果更好,有興趣可以去看上面各種範例。
from transformers import AutoTokenizer, AutoModel
import torch
def get_embeddings(model_name, sentence):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
emb_all = []
inputs = tokenizer(sentence, return_tensors='pt', padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
return embeddings
sentence = "台大歷史最悠久,且最具代表之綜合性高等教育學府"
model1_embeddings = get_embeddings('ckiplab/bert-base-chinese', sentence)
model2_embeddings = get_embeddings('hfl/chinese-bert-wwm', sentence)
import umap
def reduce_dimensions(embeddings):
reducer = umap.UMAP(n_neighbors=2, min_dist=1.0)
return reducer.fit_transform(embeddings)
model1_reduced = reduce_dimensions(model1_embeddings.squeeze(0))
model2_reduced = reduce_dimensions(model2_embeddings.squeeze(0))
import matplotlib.pyplot as plt
import numpy as np
import umap
def plot_combined_embeddings(all_reduced, sentence):
plt.figure(figsize=(5, 5))
for idx, char in enumerate(sentence):
plt.scatter(all_reduced[idx, 0], all_reduced[idx, 1], color=plt.cm.rainbow(0))
plt.text(all_reduced[idx, 0], all_reduced[idx, 1], char, fontsize=12, color=plt.cm.rainbow(0))
plt.title("Combined BERT Model Embeddings")
plt.legend(loc="upper right", fontsize=10)
plt.show()
plot_combined_embeddings(model1_reduced[1: -1], sentence) # 頭尾有特殊token
plot_combined_embeddings(model2_reduced[1: -1], sentence)
參考連結: https://github.com/ymcui/Chinese-BERT-wwm
wwm指的就是在訓練的時候是Mask一個詞,而不是原本Mask字,這樣子更能學到詞的關係。

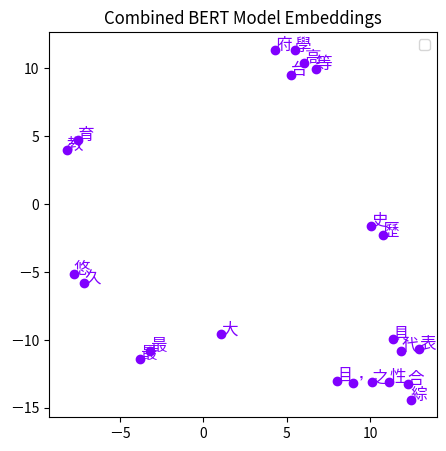
單純bert以訓練時以char做訓練
訓練bert時採用wwm
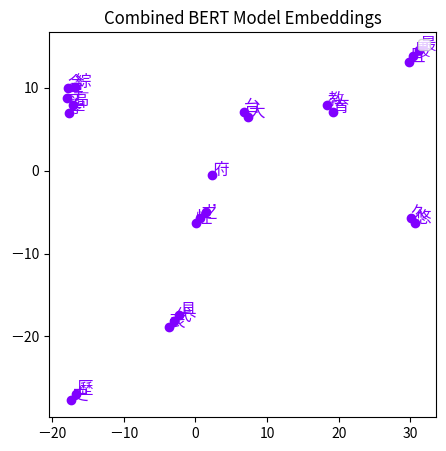
從上面兩張圖最明顯的點就是"台大"兩個字,在wwm的model,台大兩個字是非常接近的,而在一般的則是分很開,然後可以看到幾乎是一個詞的會非常接近,我自己是這樣子覺得,因為是一個詞所以他們的特徵向量非常相似。
經過這個例子就可以知道bert有學習到字語詞的關係,所以應用在downstream task效果才會那麼好。
不過這個例子是當初自己嘗試的,能不能這樣理解不知道。
今天就到這裡囉~~


 iThome鐵人賽
iThome鐵人賽